Ha sido cambiar el diseño para que pueda funcionar a frecuencias superiores a 40MHz y mano de santo. También vale poner un cristal más pequeño, pero de momento he conseguido no tener que prescindir del reloj de 40MHz (lo que me da una frecuencia máxima de SPI de 20MHz, que no está mal).
Y tanto que no está mal. Ahora sí que he podido pisar el acelerador y poner la tarjeta SD a 20MHz.
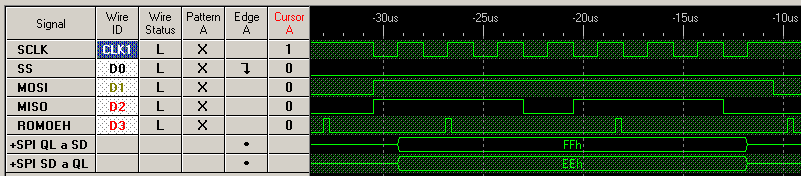
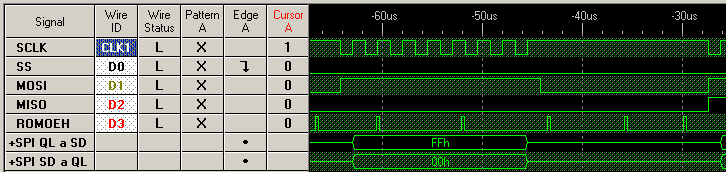
Cada "borrón" amarillo en SCLK se corresponde a 8 períodos de reloj. Le he hecho zoom "alejado" para que se puedan ver tres transferencias completas. Se puede observar cómo ahora el pulsito de ROMOEH tiene una anchura del mismo orden que la ráfaga de SCLK.
Esta secuencia se corresponde con un bucle de lectura de datos tal que éste:
Código: Seleccionar todo
move.b (a2),d7 ; pido una nueva transmisión de dato en SPI. Lo que haya en D7 lo descarto.
move.b (a1),(a0)+ ; leo el dato recién tráido de la SD y lo guardo en memoria.
Con A1 = $FFFC, que es el registro que guarda el último dato leído del SPI, y A2 = $FEFF, que al leerse realiza un envío "vacío" al bus SPI (ya vimos que para poder recibir hay que enviar algo). A0 apunta al buffer de memoria que guardará el sector leído de la SD. En las pruebas, A0 apunta a algún lugar de la pantalla del QL.
Estas dos instrucciones se repiten 512 veces, para leer un sector completo. En la línea de -20us de la imagen, el pulsito de ROMOEH que cae justo en esa línea se corresponde con el primer move.b, que lee de un registro en la interfaz que provoca que se generen los 8 pulsos de reloj. La transferencia dura mucho menos de lo que el procesador tarda en leer y ejecutar la siguiente instrucción, así que ni me molesto en ver si el bit de "ocupado" está activo, porque sé que no lo estará. Unos dos microsegundos más tarde comienza el segundo move.b que lee del registro de salida SPI el dato recién recibido y lo guarda en memoria con autoincremento. El autoincremento "cuesta" y por eso este segundo move dura más que el primero, como puede observarse.
Esto se puede mejorar. Uso dos instrucciones: una que hace de "pistoletazo de salida" para que un nuevo dato llegue corriendo desde la SD hasta la interfaz, y otra instrucción que recoge ese dato y lo guarda en memoria RAM. ¿Y si aprovechamos la instrucción que recoge el dato para que a la vez que lo recoge, pida uno nuevo? Es decir, una especie de "pipeline".
El resultado es éste:
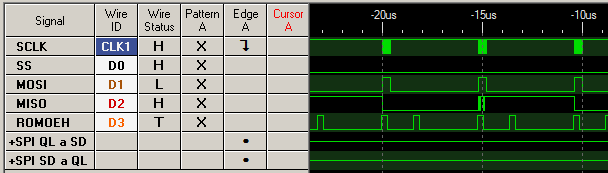
Que se corresponde con esta instrucción:
En este caso, A1 = $FFFC
Esta instrucción lee del registro de salida de SPI, guarda lo leído en memoria con autoincremento, y señaliza una nueva transmisión de datos. De un move al siguiente, como se ve, hay tiempo de sobra para que la transmisión SPI termine (yendo a 20MHz, claro). Creo que la ULA del QL mete un retraso cuando se intenta leer de las posiciones reservadas a la ROM del sistema y de ampliación, que es donde estamos nosotros. Este va a ser seguramente el mayor cuello de botella que nos encontremos. No es posible ir más rápido.
¿O sí...? Hay una cosa que no hemos probado: el 68008 tiene un bus de datos de 8 bits y todas las transferencias externas son de 8 bits, pero... hay instrucciones como move.l que mueven 32 bits de un sitio a otro, a base de hacer 4 transferencias seguidas. Esto debe ser más rápido por fuerza que 4 instrucciones move.b
Así que he cambiado el diseño de la CPLD para que en lugar de haber un registro de 8 bits, haya 4 registros de 8 bits cada uno. En realidad son todos el mismo, pero como cada vez que se lee uno, se pide un nuevo dato, al leer el siguiente registro (o el mismo), obtenemos siempre un nuevo dato.
Es decir: si para leer un nuevo dato y pedir el siguiente lo que se hace es leer de la posición $FFFC, ahora podemos hacer esta msma operación también en las direcciones $FFFD, $FFFE y $FFFF.
Así que si hago un:
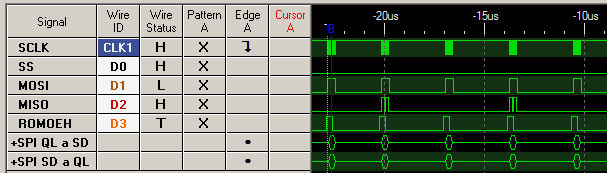
Con A1 = $FFFC, lo que el procesador hace son 4 lecturas seguidas de las posiciones FFFC,D,E y F. En efecto:
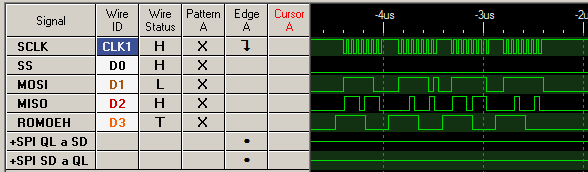
Al contrario que en los gráficos anteriores, aquí muestro un zoom más detallado, donde se ven las 4 transferencias del move.l . No se me ocurre una forma de ir más rápido, por lo que pondré el techo de tasa de trasnferencia aquí. OJO porque la instrucción anterior tiene postincremento, y éste tarda unos cuántos microsegundos, así que cuando se concatenan varias instrucciones move.l seguidas lo que se obtiene son una serie de ráfagas cortas como la anterior, seguidas de alrededor de 4 microsegundos de silencio por el postincremento.